案例介绍
本案例将使用多类别支持向量机(Multi-Class Support Vector Machine,MC-SVM)对鸾尾花(Iris)数据集进行分类。鸢尾花数据集是一个常用的分类问题数据集,包含了三种不同类别的鸢尾花样本,具体为Setosa、Versicolor和Virginica。我们的目标是根据花的特征,使用MC-SVM对这些鸢尾花进行分类。
算法原理
多类别支持向量机是通过将多个二分类问题相互比较来进行多类别分类的。一种常用的方法是一对一(One-vs-One)策略,在该策略下,每个类别之间都有一个分类器。假设有K个类别,那么将会有K * (K-1) / 2个分类器。每个分类器只关注其两个类别之一,对于属于其中一个类别的样本,将其标记为正例,而对于属于另一个类别的样本,将其标记为负例。最后,使用投票机制来确定对新样本的分类结果,即选择获得最多正例标签的类别作为最终的分类结果。
在MC-SVM中,我们可以使用与二分类SVM类似的方法来训练分类器。对于每对类别之间的二分类任务,我们通过最小化带有正则化项的目标函数来找到一个最优的超平面。该目标函数可以用以下公式表示:
$$
\min_{w,b} \frac{1}{2}w^Tw + C\sum_{i=1}^{n}\xi_{i}
$$
其中,$w$是超平面的法向量,$b$是偏置项,$\xi_{i}$是松弛变量,n是样本数量,C是惩罚参数,用于控制误分类样本和决策边界之间的平衡。
Soft Margin
与二分类SVM类似,我们还可以使用软间隔(Soft Margin)来容忍某些样本的误分类。此时,目标函数需要加入松弛变量项,公式为:
$$
\min_{w,b,\xi} \frac{1}{2}w^Tw + C\sum_{i=1}^{n}\xi_{i}
$$
同时,我们需要满足以下约束条件:
$$
y_{i}(w^Tx_{i} + b) \geq 1 – \xi_{i}, \forall i
$$
$$
\xi_{i} \geq 0, \forall i
$$
其中,$x_{i}$表示样本特征,$y_{i}$为对应的类别标签。
数据集
本案例使用鸢尾花(Iris)数据集,该数据集包含150个样本,每个样本有4个数值型特征:萼片长度(sepal length)、萼片宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。每个样本都属于以下三个类别之一:Setosa、Versicolor或Virginica。
计算步骤
- 导入所需的库和鸢尾花数据集。
- 对数据集进行预处理,包括划分为训练集和测试集,并进行归一化处理。
- 定义MC-SVM模型,并使用训练集进行训练。
- 使用测试集评估模型的性能。
- 可选:可视化决策边界。
Python代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import SVC
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征归一化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 定义MC-SVM模型
model = OneVsOneClassifier(SVC())
# 模型训练
model.fit(X_train_scaled, y_train)
# 模型预测
y_pred = model.predict(X_test_scaled)
# 准确率评估
accuracy = np.mean(y_pred == y_test)
print("Accuracy:", accuracy)
# 可视化决策边界(仅适用于2个特征)
if X_train_scaled.shape[1] == 2:
h = 0.02 # 步长
x_min, x_max = X_train_scaled[:, 0].min() - 1, X_train_scaled[:, 0].max() + 1
y_min, y_max = X_train_scaled[:, 1].min() - 1, X_train_scaled[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=y_train, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Decision boundary')
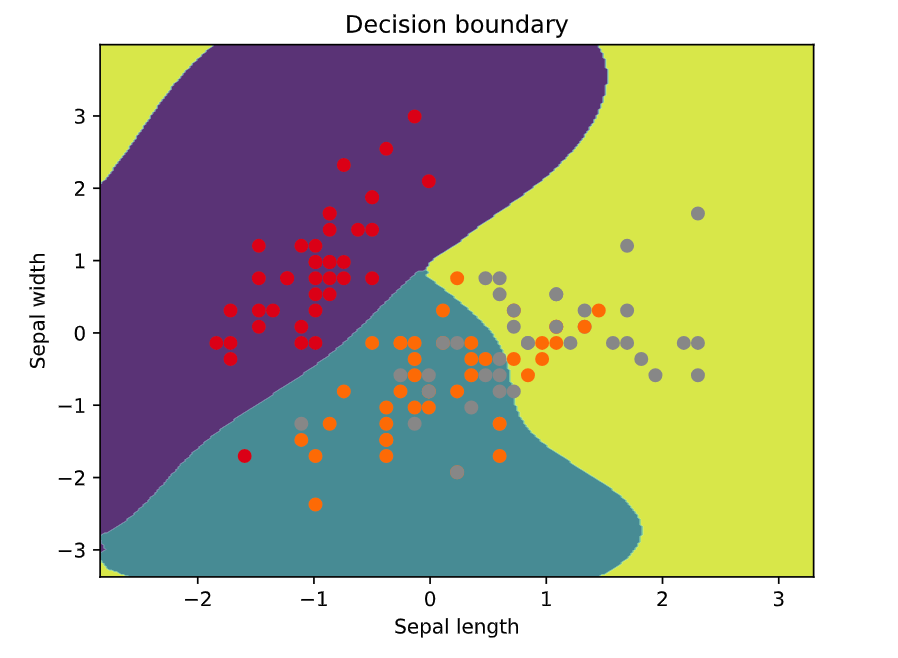
plt.show()限制2个特征的代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import SVC
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 仅选择前两个特征
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征归一化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 定义MC-SVM模型
model = OneVsOneClassifier(SVC())
# 模型训练
model.fit(X_train_scaled, y_train)
# 模型预测
y_pred = model.predict(X_test_scaled)
# 准确率评估
accuracy = np.mean(y_pred == y_test)
print("Accuracy:", accuracy)
# 可视化决策边界
h = 0.02 # 步长
x_min, x_max = X_train_scaled[:, 0].min() - 1, X_train_scaled[:, 0].max() + 1
y_min, y_max = X_train_scaled[:, 1].min() - 1, X_train_scaled[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=y_train, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Decision boundary')
plt.show()
代码细节解释
- 首先导入所需的库和鸢尾花数据集。
- 使用
train_test_split函数对数据集进行划分,将80%的数据用于训练,20%的数据用于测试。 - 使用
StandardScaler对训练集和测试集进行数据归一化处理。 - 创建
OneVsOneClassifier对象,并指定使用SVC作为基分类器。 - 使用训练集调用
fit方法,对模型进行训练。 - 使用测试集调用
predict方法,对新样本进行预测。 - 使用准确率评估模型的性能。
- 可选:若特征维度为2,则绘制决策边界图,用不同颜色表示不同类别的样本。
通过以上步骤,我们可以使用多类别支持向量机对鸢尾花数据集进行分类,并评估模型的性能。
评论(2)
第一份代码最后绘图时不会有任何输出,因为鸢尾数据是4个特征,而绘图时限定为2个特征时才进行画图。若修改if条件为4的话,将尝试用四个特征画二维图进而报错。
仅适用于2个特征