案例介绍
在这个案例中,我们将使用层次聚类算法对一个虚拟数据集进行聚类。我们将首先介绍基本的层次聚类算法原理并推导公式,然后使用Python实现该算法,并对数据集进行聚类,并绘制聚类结果。
算法原理
层次聚类是一种无监督学习算法,通常用于将数据集划分为不同的类别。该算法使用距离或相似度指标来测量数据点之间的相似度,并递归地将最相似的数据点或簇合并在一起,最终形成一个聚类树(树状图)。在层次聚类中,有两种主要方法:凝聚聚类和分裂聚类。
凝聚聚类(Agglomerative Clustering) 是一种自下而上的方法,其步骤如下:
- 将每个数据点分别初始化为一个簇。
- 计算所有数据点对之间的相似度或距离。
- 找到最相似的两个簇(根据相似度或距离度量),将它们合并为一个新的簇。
- 更新相似度矩阵,去掉合并的两个簇,并添加新的合并簇。
- 重复步骤3和步骤4,直到只剩下一个簇。
分裂聚类(Divisive Clustering) 是一种自上而下的方法,其步骤如下:
- 将所有数据点初始化为一个簇。
- 计算簇中所有数据点的平均值作为中心点。
- 将簇中所有数据点与该中心点的距离作为相似度度量。
- 找到相似度最低的数据点作为分割点,将簇分为两个子簇。
- 递归地对子簇重复步骤2至步骤4,直到达到预定的聚类数量或满足其他停止条件。
在本案例中,我们将使用凝聚聚类方法。
公式推导
在凝聚聚类中,我们需要计算两个簇($C_i$ 和 $C_j$)之间的相似度或距离。一种常用的相似度度量是欧式距离(Euclidean Distance),其公式为:
$$
\mathrm{EuclideanDistance}(C_i, C_j) = \sqrt{\sum_{\forall x_i \in C_i} \sum_{\forall x_j \in C_j} (x_i – x_j)^2}
$$
数据集
我们将使用一个由三个二维数据簇组成的虚拟数据集。每个数据簇都包含30个数据点,总共有90个数据点。
import numpy as np
np.random.seed(0)
cluster1 = np.random.randn(30, 2) + np.array([0, 7])
cluster2 = np.random.randn(30, 2) + np.array([8, 0])
cluster3 = np.random.randn(30, 2) + np.array([8, 8])
data = np.vstack([cluster1, cluster2, cluster3])数据集包含90行和2列,每一行代表一个数据点,2列分别代表该数据点在二维空间中的两个坐标。
计算步骤
- 初始化每个数据点为一个独立的簇。
- 计算簇中心之间的距离,并找到最近的两个簇。
- 合并最近的两个簇为一个新的簇,并更新簇中心点。
- 重复步骤2和步骤3,直到只剩下一个簇。
Python代码示例
下面是使用Python实现层次聚类算法的完整代码示例,并绘制聚类结果的图表。
import numpy as np
import matplotlib.pyplot as plt
# 1. 初始化每个数据点为一个独立的簇
def initialize_clusters(data):
return [[point] for point in data]
# 2. 计算簇中心之间的距离,并找到最近的两个簇
def compute_distances(clusters):
distances = np.zeros((len(clusters), len(clusters)))
for i in range(len(clusters)):
for j in range(len(clusters)):
if i != j:
# 使用欧式距离计算两个簇的距离
distances[i][j] = np.sqrt(sum((np.mean(clusters[i], axis=0) - np.mean(clusters[j], axis=0))**2))
return distances
def find_closest_clusters(distances):
min_distance = np.inf
closest_clusters = None
for i in range(len(distances)):
for j in range(len(distances)):
if i != j and distances[i][j] < min_distance:
min_distance = distances[i][j]
closest_clusters = (i, j)
return closest_clusters
# 3. 合并最近的两个簇为一个新的簇,并更新簇中心点
def merge_clusters(clusters, closest_clusters):
i, j = closest_clusters
merged_cluster = clusters[i] + clusters[j]
new_clusters = [cluster for idx, cluster in enumerate(clusters) if idx not in (i, j)]
new_clusters.append(merged_cluster)
return new_clusters
def hierarchical_clustering(data):
# 初始化每个数据点为一个独立的簇
clusters = initialize_clusters(data)
# 开始迭代合并最相似的簇直到只剩下一个簇
while len(clusters) > 1:
# 计算簇中心之间的距离,并找到最近的两个簇
distances = compute_distances(clusters)
closest_clusters = find_closest_clusters(distances)
# 合并最近的两个簇为一个新的簇,并更新簇中心点
clusters = merge_clusters(clusters, closest_clusters)
return clusters
# 执行层次聚类算法
clusters = hierarchical_clustering(data)
# 打印聚类结果
for idx, cluster in enumerate(clusters):
print(f"Cluster {idx+1}: ", cluster)
# 绘制聚类结果的图表
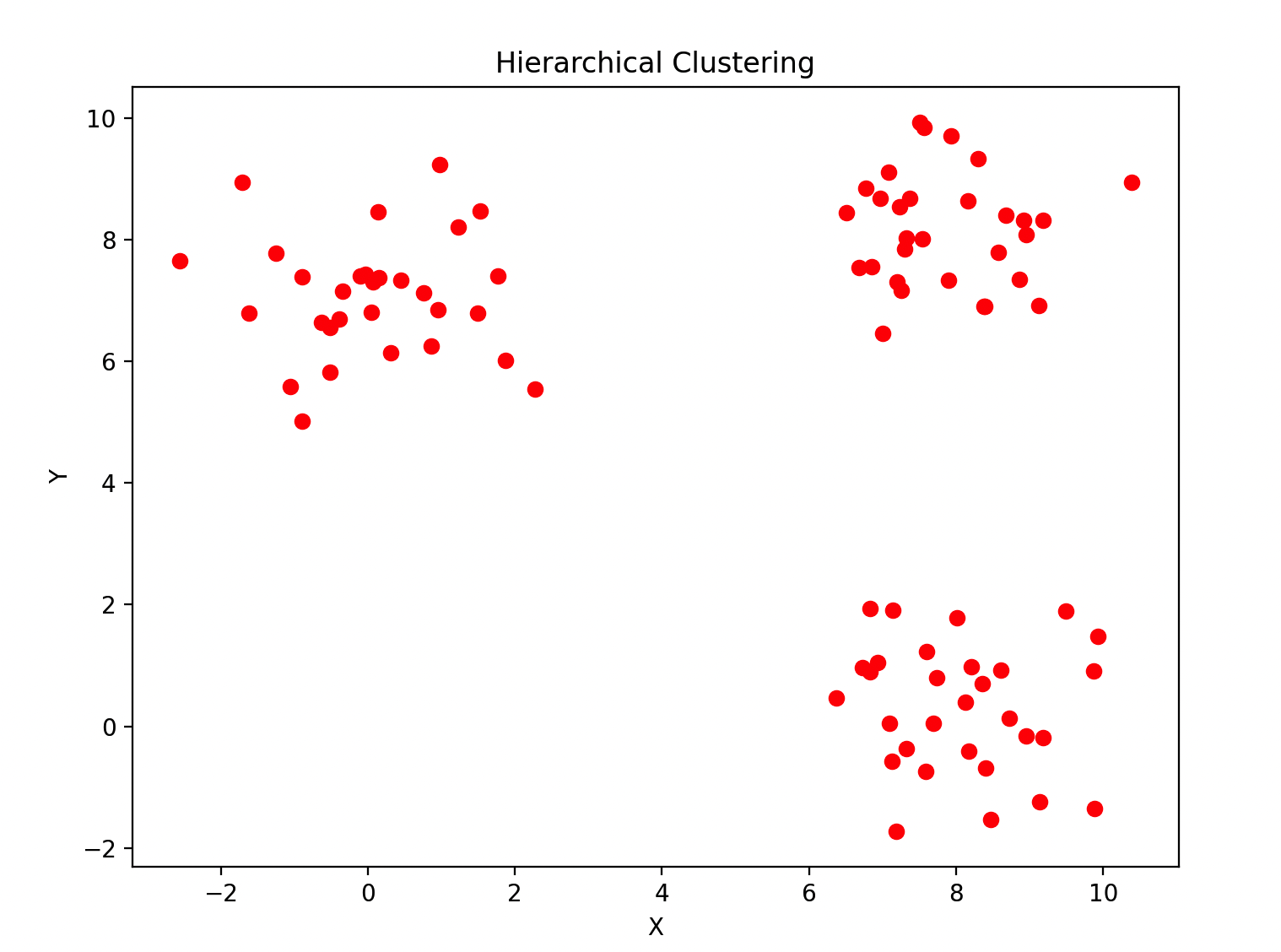
plt.figure(figsize=(8, 6))
colors = ["red", "green", "blue"]
for idx, cluster in enumerate(clusters):
plt.scatter(*zip(*cluster), color=colors[idx])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Hierarchical Clustering")
plt.show()
代码细节解释
initialize_clusters(data): 初始化每个数据点为一个独立的簇。compute_distances(clusters): 计算簇中心之间的距离,并使用欧式距离计算两个簇之间的距离。find_closest_clusters(distances): 找到距离最近的两个簇。merge_clusters(clusters, closest_clusters): 合并最近的两个簇为一个新的簇,并更新簇中心点。hierarchical_clustering(data): 执行层次聚类算法,迭代合并最相似的簇直到只剩下一个簇。- 绘制聚类结果的图表。
以上代码将给定的虚拟数据集进行了层次聚类,并且打印出了每个聚类簇的数据点以及绘制了聚类结果的图表。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(4)
plt.scatter(*zip(*cluster), color=colors[idx])这句话执行错误,提示TypeError: ‘numpy.float64’ object is not iterable
已修复!
画图指定的颜色并未生效
原因是分类的时候while len(clusters) > 1:最后将所有的簇都分为了一类。导致画出来的都是红的。